导读:从“经验试错”到“理性设计”的迫切需求
界面聚合微胶囊化(MIP)技术是制备自修复材料、药物递送载体及功能性涂层的基石。然而,与侧重于纳米级筛分的分离膜制备不同,微胶囊制备的核心诉求在于最大化封装效率与精准调控壳层结构。MIP过程本质上是发生在油水界面的复杂多相反应,反应动力学、分子扩散与相分离过程深度耦合,且高度依赖于单体的分子特性(如亲疏水性、反应活性)。
长期以来,由于缺乏能够关联分子结构、工艺参数与最终性能的定量模型,科研人员在面对疏水分子、亲水分子乃至高活性物质(如异氰酸酯)的封装时,往往陷入“盲目试错”的困境。传统的分离膜理论难以直接套用,导致微胶囊领域长期停留在“经验驱动”阶段。因此,建立一套能够解析“反应-扩散”竞争机制、指导高性能微胶囊可编程合成的量化框架,已成为该领域突破瓶颈的关键。

文章亮点:构建全球首个MIP定量设计平台
针对微胶囊界面聚合(MIP)缺乏理性设计准则的行业痛点,香港科技大学团队在《Advanced Materials》发表了题为“Programming Interfacial Polymerization: Machine Learning Unveils Quantitative Rational Design Rules for Microcapsules and Beyond”的研究。该研究开创性地将可解释机器学习引入微胶囊合成领域,建立了一套基于物理机制的数据驱动设计范式。
研究团队首先构建了全球首个界面聚合微胶囊化(MIP)领域的分子–工艺–结构–性能(CPSP)数据库(图2),系统整合了O/W(水包油)和W/O(油包水)体系的海量实验数据。在此基础上,他们开发了微胶囊智能设计平台(图1),不再依赖单一变量试错,而是通过算法深度挖掘数据背后的物理化学机制。
该研究确立了以分配系数(Log P)和Mayr反应活性为核心的分子描述符体系。通过对模型的可解释性分析(图3),团队首次量化揭示了O/W与W/O体系的根本性差异:
在O/W体系中,Log P(分子亲疏水性)是决定封装效率的主导因素;
在W/O体系中,Mayr反应活性则占据主导地位。
利用符号回归(Symbolic Regression)算法(图4),研究团队进一步突破了传统黑箱模型的限制,从数据中自动推导出简洁的解析表达式——即隐藏描述符。这些描述符本质上是界面Damköhler数(反应速率/扩散速率)的数学体现,清晰地量化了“反应-扩散”的协同与竞争关系,定义了获得高封装效率的“黄金窗口”。
这套量化准则直接赋能了高通量虚拟微胶囊设计(图5)。研究人员在不进行实际实验的情况下,对数万种虚拟配方进行了快速扫描,成功将材料设计空间拓展了数百倍。基于虚拟筛选推荐的配方,团队进行了系统的实验验证(图6),成功实现了从疏水分子(如甲苯二异氰酸酯TDI)到亲水分子的普适性高效封装,预测值与实验值高度吻合。进一步地,该设计法则被应用于功能化微胶囊的构筑(图7),实现了超疏水表面(接触角>150°)的精准调控以及基于二硫键动态可逆特性的自修复微胶囊设计,验证了其在实际应用中的强大潜力。
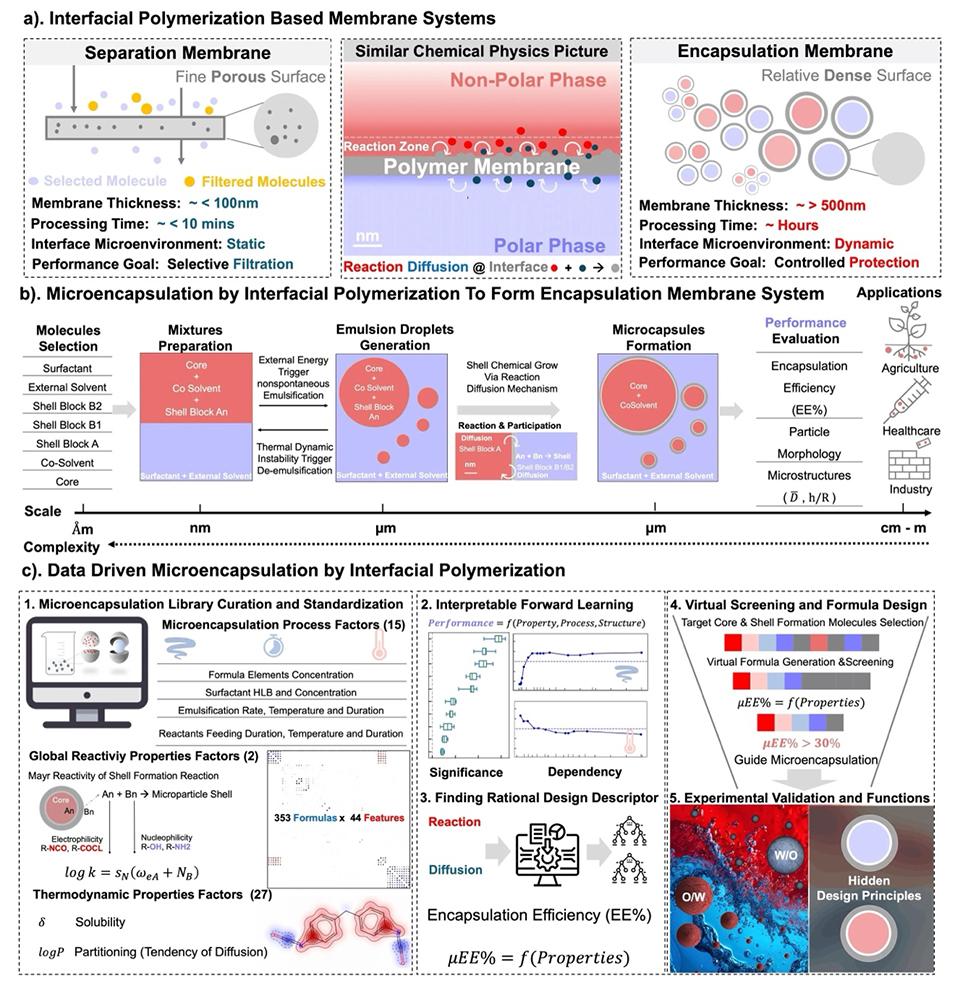
图1:一个基于物理信息的、数据驱动的预测性微胶囊化设计平台。(a)界面聚合法制备的分离膜和胶囊化膜的主要区别。(B)界面聚合法制备的传统微胶囊化的物理规模和复杂性说明。(c)界面聚合法制备微胶囊化的信息化过程。
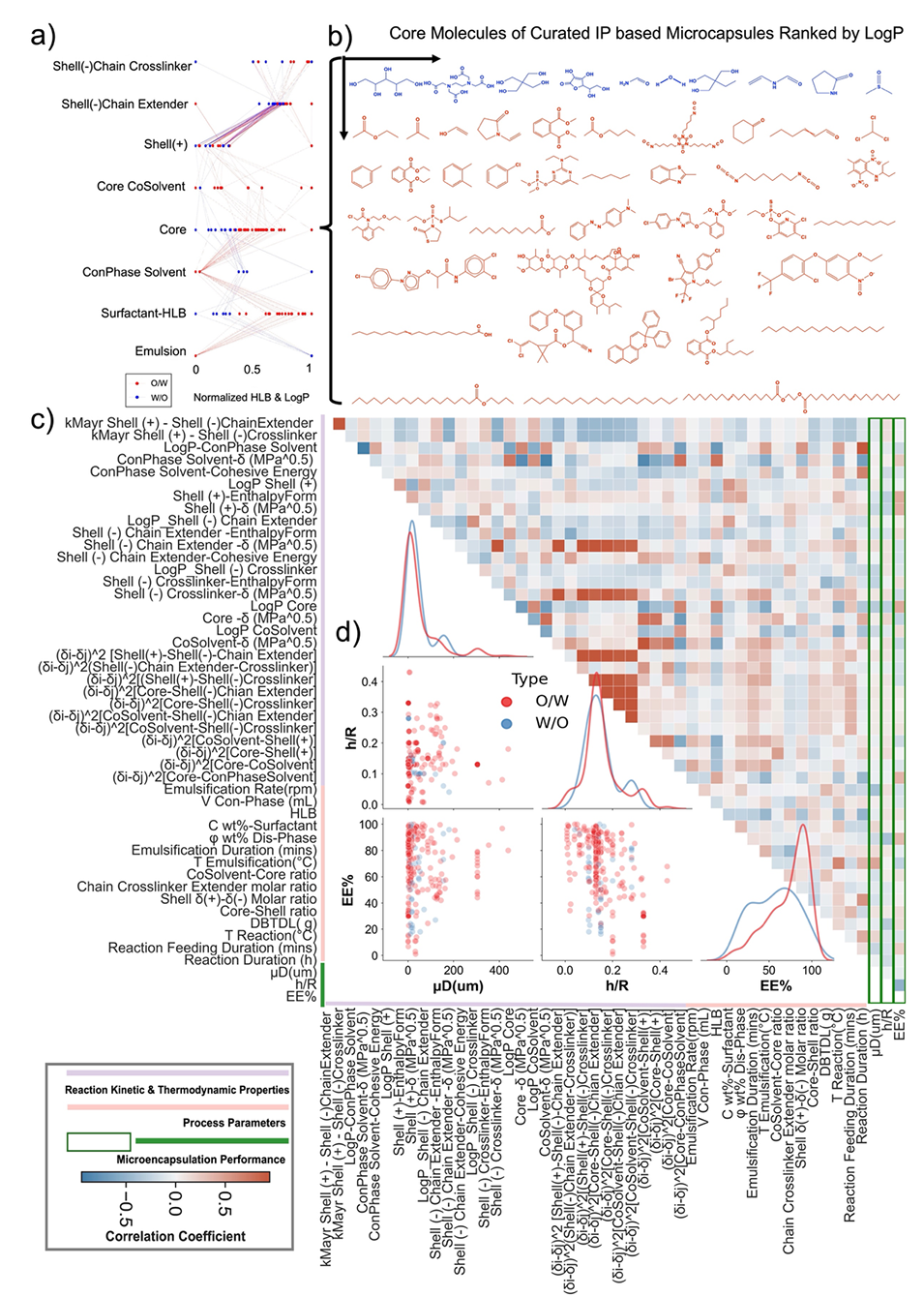
图2:界面聚合法制备微胶囊的化学-工艺-结构-性能(CPSP)库。(a)微胶囊分子组成的层次关系。(B)CPSP库中核心分子的多样性。(c)MIP性质-工艺-结构-性能关系的多重共线性图。(d)微胶囊的包封率、平均粒径、和壳厚半径比。
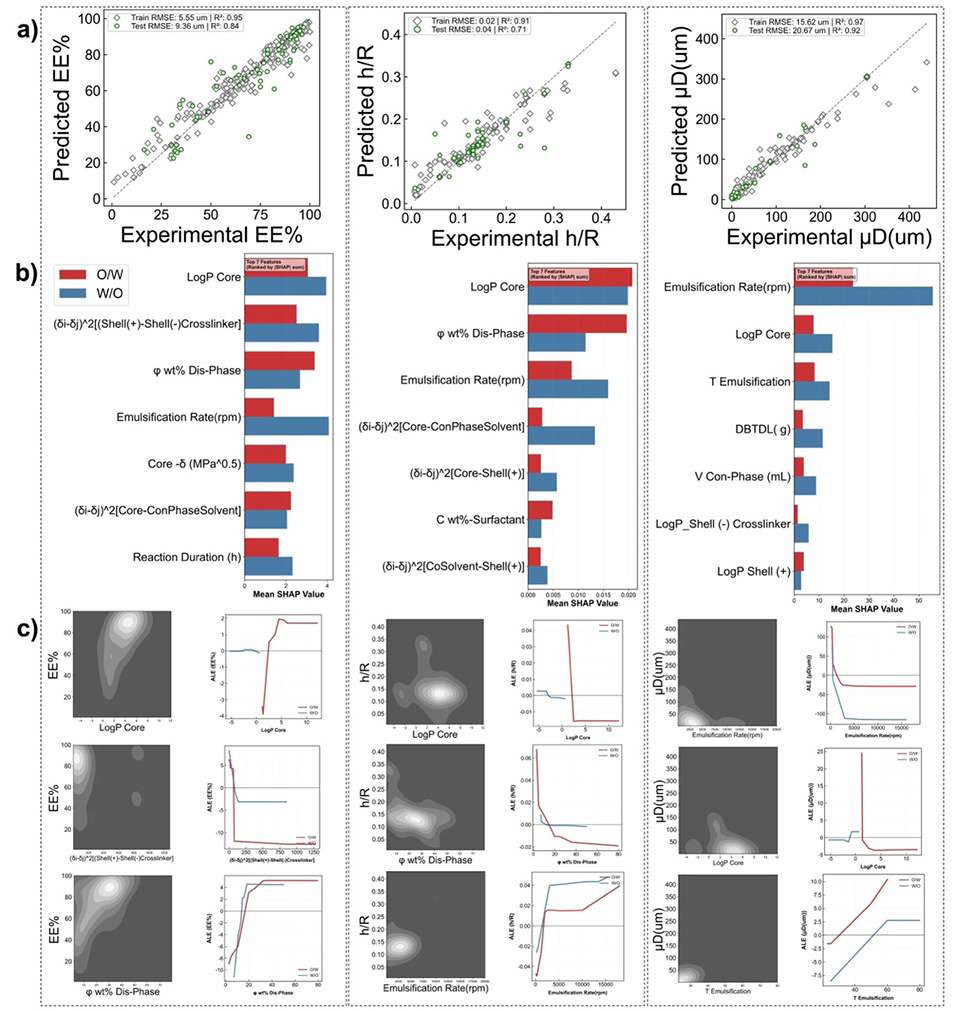
图3.1:可解释机器学习的性能。(a)选择和调整随机森林模型预测包封率,壳厚度,半径比,和平均微粒直径。策展的数据集被分成242个训练数据点和60个测试数据点。上述预测结果通过均方根误差进行评估。(B)Shapley加法解释(SHAP)对每三个随机森林模型的前7个特征的重要性进行了总结分析。通过解耦W/O和O/W效应来说明每个特征对相应预测目标的影响。(c)前3个特征的原始依赖性(左)和估计依赖性与相应目标通过累积局部效应(ALE)值可视化,其反映一维特征与估计目标(右)的关系。
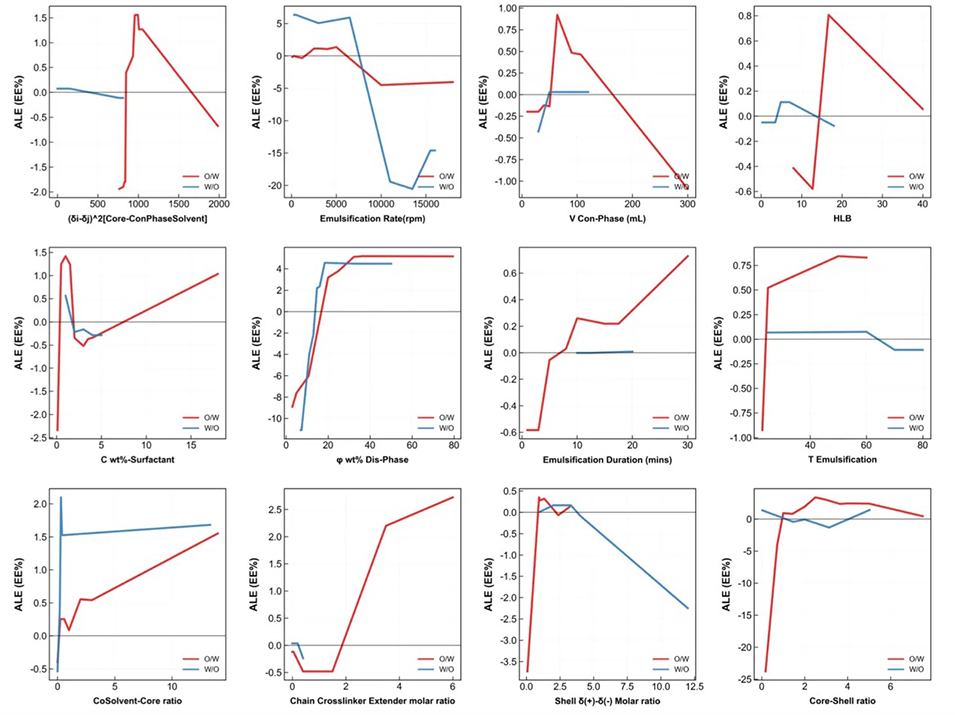
图3.2 微胶囊化工艺参数偏依赖性的ALE解耦(原文Figure S7)
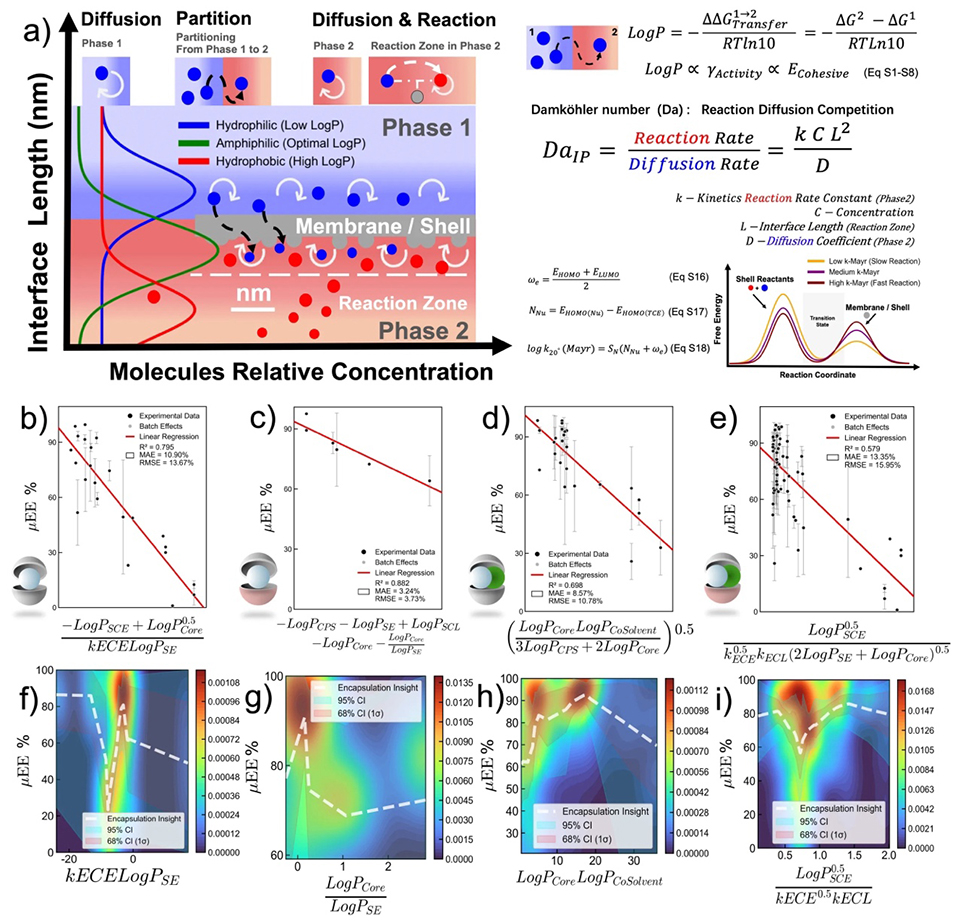
图4:通过符号Transformer和偏相关分析提取的µEE%和颗粒形态的隐藏组成描述符。符号Transformer使用Pearson相关系数作为训练选择标准来实现。(a)界面聚合的示意图,强调界面处扩散和反应之间的竞争。该过程由分配系数(log P)控制,其设定了相转移的热力学驱动力,并通过界面聚合的达姆科勒数(Da-IP),它测量反应速率与扩散传输的比率。能量图(右)显示了与不同反应动力学(k-Mayr)相关的活化势垒。(B)描述符用于具有单核和仅扩链剂的二进制系统(模型A)。(c)描述符用于具有单核、扩链剂、和交联剂(模型B)。(d)仅含扩链剂的核/共溶剂混合物的描述符(模型C)。(e)混合分子制剂的描述符(模型D)。。误差线代表微胶囊化批次条件引起的变异性。(f-i)二维部分依赖图显示了模型A-D中的非线性描述项对如何分别控制µEE%。白色虚线、暖态和冷态概率密度区域表示基础物理因子之间的协同增强和竞争机制。
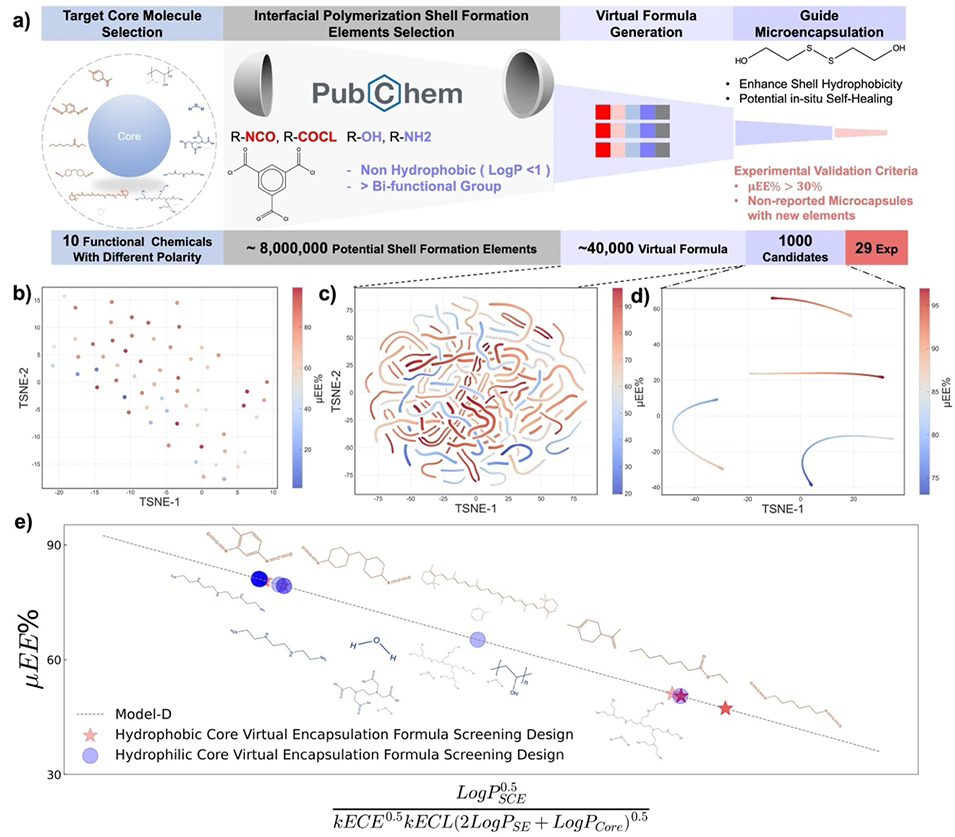
图5:界面聚合微胶囊化的高通量虚拟设计过程(a)微胶囊虚拟设计的四个关键步骤的示意图。这些步骤包括选择目标核心分子、识别适当的成壳组分、生成虚拟配方,最后,微胶囊的实验合成。(B)微胶囊初始库的材料设计空间的降维可视化。它不显示单个实验批次。相反,它通过聚合每个不同核-壳分子组合的批次数据并将其映射到归一化描述符空间来可视化材料水平点。对于每个核-壳系统,分子描述符(从SMILES计算)和选定的工艺描述符在所有相应批次中进行标准化和平均,在选定的描述符空间中为每个配方产生一个代表性点。(c)40 000个虚拟微胶囊的材料设计空间,展示了对潜在配方的扩展探索;(d)1 000个虚拟微胶囊的精细材料设计空间,根据最低包封效率和未报告微胶囊的新奇性标准进行过滤;(e)通过提取的成分描述符对不同设计配方进行初始分子封装筛选。
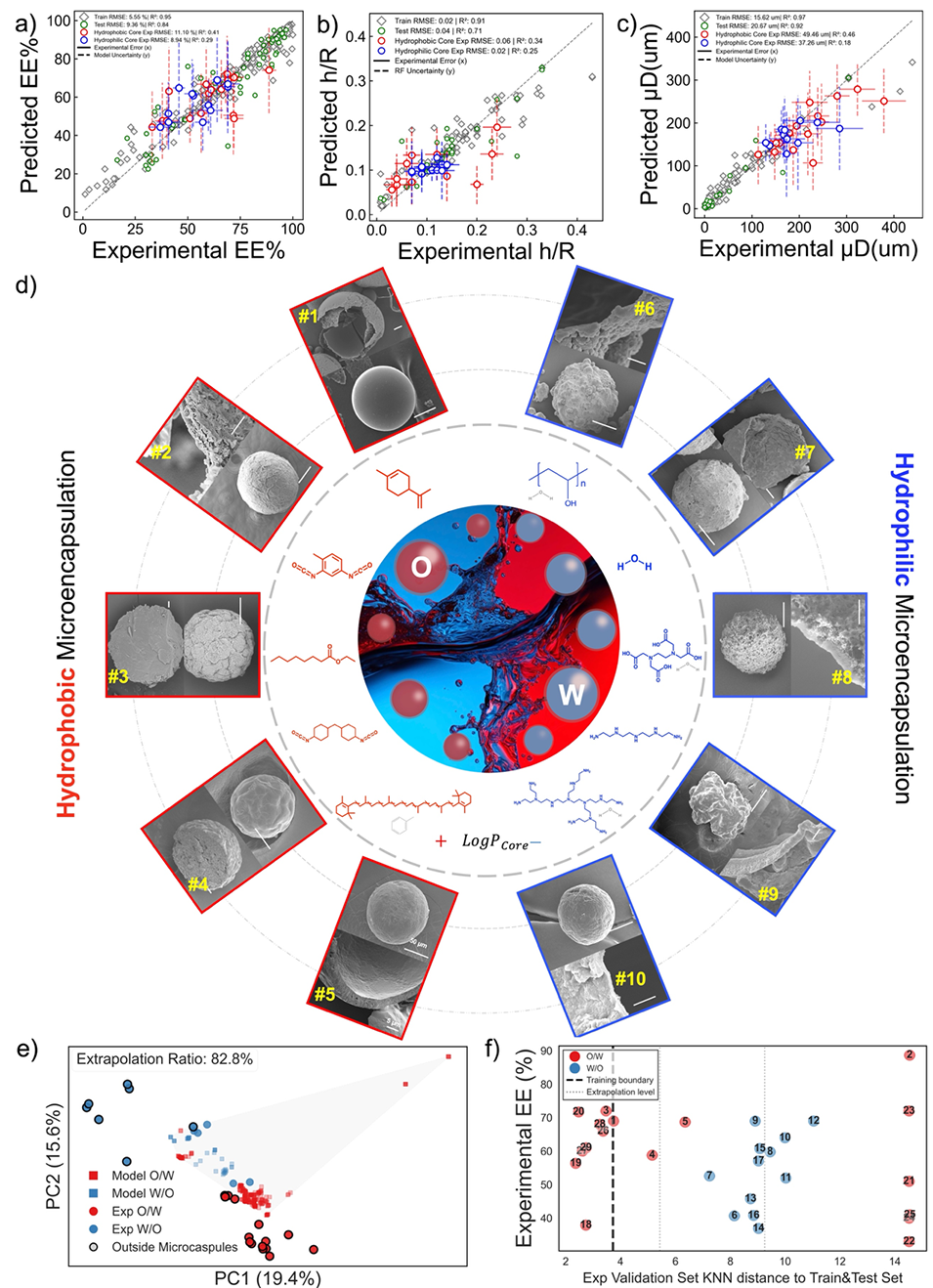
图6:从疏水性和亲水性封装广泛的化学品的预测模型的实验验证。(a)包封率的外推估计性能。(B)壳厚半径比的外推估计性能。(c)平均粒径的外推估计性能。(d)验证的疏水和亲水核微粒的微观结构和相应的横截面形态。(e)主成分分析(PCA)可视化模型训练数据相对于实验验证点的特征空间分布。(f)通过使用K最近邻(KNN)距离来定义微粒外推域。比例尺,(d)内圆为50 µm,(d)外圆为5 µm,数据表示为平均值±SD(N = 3个独立重复样本)。
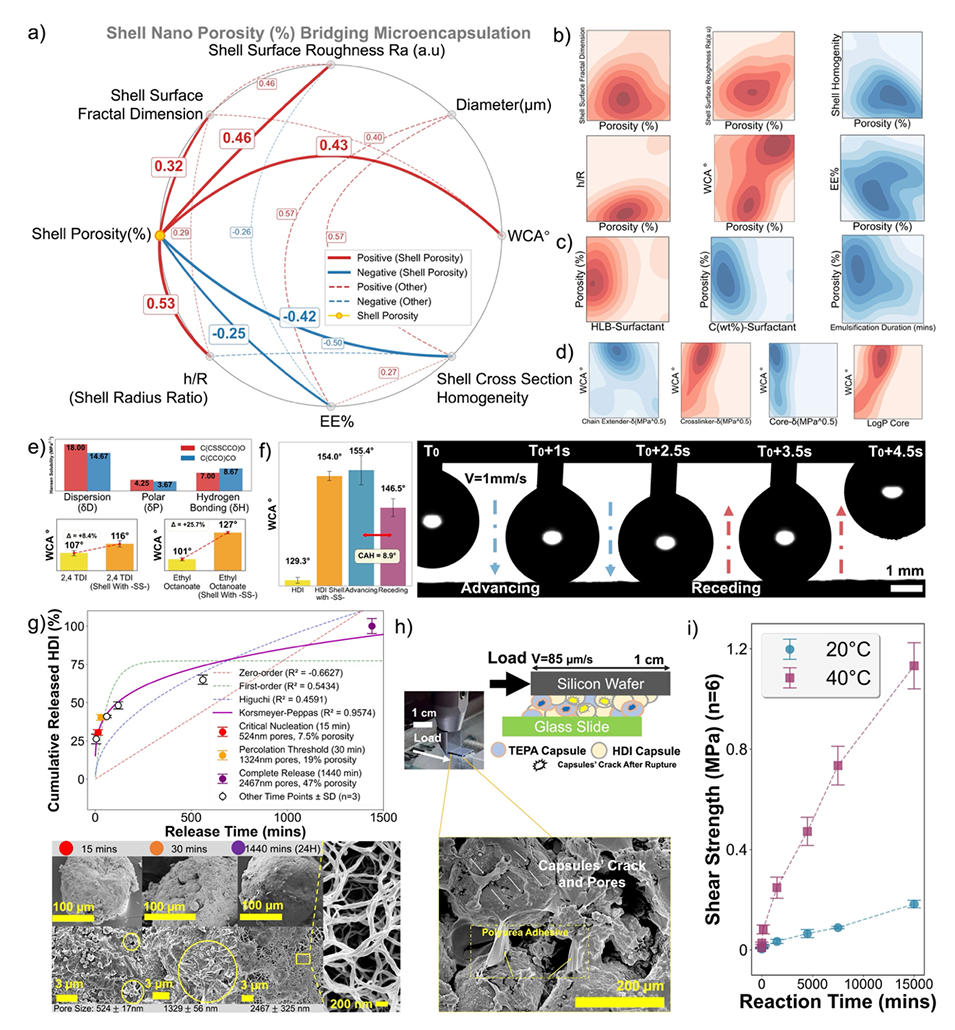
图7:具有超疏水和自我修复功能的孔隙率可调微胶囊的合理设计和多尺度表征。(a)Pearson相关网络分析揭示了壳纳米孔隙率%作为连接微胶囊化性能、微胶囊的纳米结构和微结构与功能性质的桥接参数。红色和蓝色线分别表示正相关和负相关。(b-d)绘制多维参数空间的等高线图:(B)孔隙率对微胶囊化性能、结构描述符和水接触角的影响;(c)MIP代表性加工参数对控制孔隙率的影响;以及(d)控制微胶囊表面润湿性的化学性质关系。红色和蓝色轮廓线表示正相关和负相关。(e-f)合理设计表面化学和润湿性分析:(e)汉森溶解度参数(HSP),解释了通过分散相互作用的接触角增强,比较#2和#25、#3和#26;(f)二硫键(SS)对HDI微胶囊(#20)的静态和动态润湿性和接触角滞后(CAH)的影响。控释过程中的释放动力学和形态演变:HDI的累积释放曲线符合各种动力学模型(零级、一级、Higuchi、Korsmeyer-Peppas),与随时间推移的孔隙和孔隙率膨胀的SEM观察结果相关。(h-i)基于HDI(#20)和TEPA(#9)微胶囊的粘合剂的剪切强度性能评价:(h)搭接剪切试验装置和SEM断口形貌的示意图,显示了释放的聚脲粘合剂的失效横截面;(i)不同温度下固化过程中的剪切强度演变(20 ℃对40 ℃),突出显示了热加速愈合效率。(N = 3个独立样品用于控释表征,N = 10个独立样品用于静态和动态WCA试验,N = 6个独立样品用于剪切强度试验)。
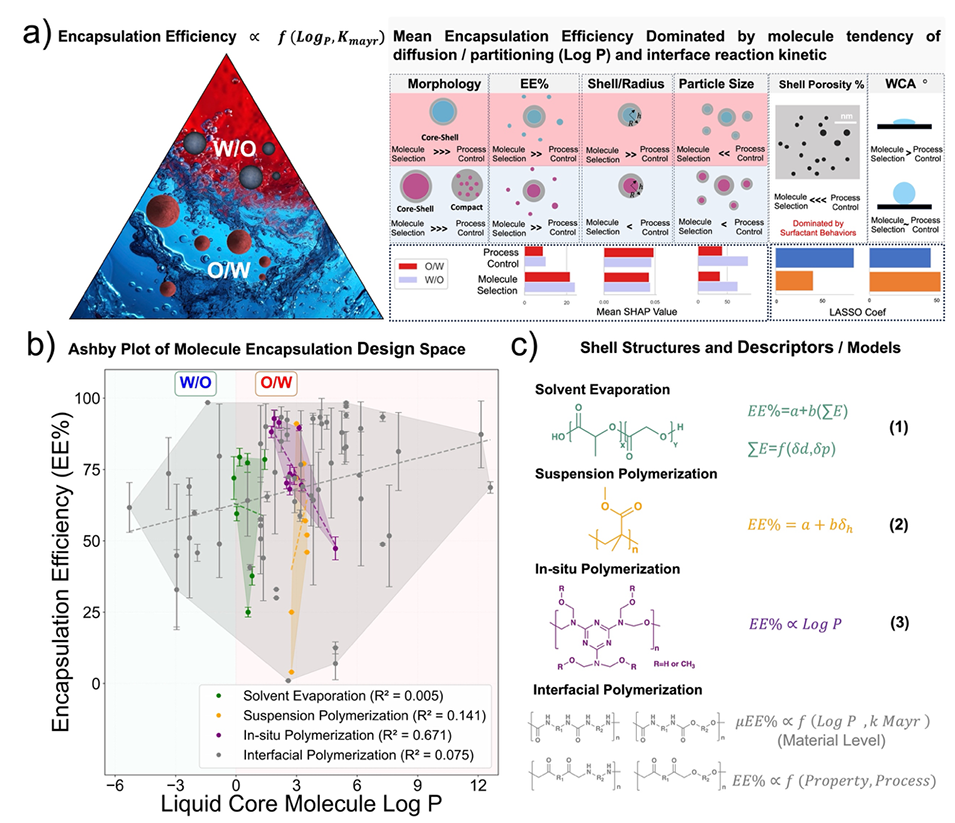
图8:通过界面聚合的微胶囊化的合理设计指南和现有的用于预测包封效率(EE%)的包封膜系统设计工具的比较(a)不同MIP性能和乳液系统的分子选择和过程控制权衡(B)用核心分子的Log P说明的包封系统选择的Ashby图;(c)不同微胶囊化方案的壳结构和预测EE%的相应描述符/模型的比较
研究意义:定义微胶囊设计的广义空间
这项研究的最大贡献在于,它打破了微胶囊界面聚合长期依赖经验的“黑箱”状态,将其转化为一套可量化、可预测、可解释的工程科学。
通过将复杂的物理场与化学场耦合机制翻译为直观的设计语言,该工作不仅为微胶囊的封装效率(30%–95%)、粒径(100–400 μm)及壳厚比(0.005–1)提供了精准的调控指南,更通过图8系统定义了微胶囊复合材料的广义设计空间。这为后续研究者指明了从分子选择、工艺优化到功能拓展的创新路径,也为催化微反应器、智能传感等其他涉及界面聚合的前沿领域提供了全新的方法论借鉴。
原文链接:
https://advanced.onlinelibrary.wiley.com/doi/abs/10.1002/adma.202517708